|Windows Process & Threads Programming 4 |Main |Windows Process & Threads Programming 6 |Site Index |Download |
MODULE T4
PROCESSES AND THREADS: Win32/WINDOWS APIs
Part 5: Story And Program Examples
What do we have in this Module?
-
Process Security and Access Rights
-
Process Working Set
-
Thread Pooling
-
Job Objects
-
Fibers
-
Interprocess Communications Mechanism
-
Using the Clipboard for IPC
-
Using COM for IPC
-
Using Data Copy for IPC
-
Using DDE for IPC
-
Using a File Mapping for IPC
-
Using a Mailslot for IPC
-
Using Pipes for IPC
-
Using RPC for IPC
-
RPC Components
-
How RPC Works
-
Microsoft RPC
-
Proxy
-
Stub
-
Using Windows Sockets for IPC
My Training Period: yy hours. Before you begin, read someinstruction here.
| The expected abilities:
ProcessSecurity and Access Rights
The Windows NT security model enables you to control access to process objects. When a user logs in, the Microsoft® Windows® operating system collects a set of data that uniquely identifies the user during the authentication process, and stores it in an access token. This access token describes the security context of all processes associated with the user. The security context of a process is the set of credentials given to the process or the user account that created the process.You can specify a security descriptor for a process when you call theCreateProcess(),CreateProcessAsUser(), or CreateProcessWithLogonW() function. If you specify NULL, the process gets a default security descriptor. The ACLs in the default security descriptor for a process come from the primary or impersonation token of the creator. To retrieve a process's security descriptor, call the GetSecurityInfo() function. To change a process's security descriptor, call theSetSecurityInfo() function.The valid access rights for process objects include the DELETE,READ_CONTROL,SYNCHRONIZE,WRITE_DAC, and WRITE_OWNER standard access rights, in addition to the following process-specific access rights.The handle returned by the CreateProcess() function has PROCESS_ALL_ACCESS access to the process object. When you call the OpenProcess() function, the system checks the requested access rights against the DACL in the process's security descriptor. When you call theGetCurrentProcess() function, the system returns a pseudohandle with the maximum access that the DACL allows to the caller.You can request the ACCESS_SYSTEM_SECURITY access right to a process object if you want to read or write the object's SACL. Warning: A process that has some of the access rights noted here can use them to gain other access rights. For example, if process A has a handle to process B withPROCESS_DUP_HANDLE access, it can duplicate the pseudo handle for process B. This creates a handle that has maximum access to process B.
|
Value | Meaning |
PROCESS_ALL_ACCESS | All possible access rights for a process object. |
PROCESS_CREATE_PROCESS | Required to create a process. |
PROCESS_CREATE_THREAD | Required to create a thread. |
PROCESS_DUP_HANDLE | Required to duplicate a handle usingDuplicateHandle(). |
PROCESS_QUERY_INFORMATION | Required to retrieve certain information about a process, such as its exit code and priority class (seeGetExitCodeProcess() and GetPriorityClass()). |
PROCESS_SET_QUOTA | Required to set memory limits usingSetProcessWorkingSetSize(). |
PROCESS_SET_INFORMATION | Required to set certain information about a process, such as its priority class (see SetPriorityClass()). |
PROCESS_TERMINATE | Required to terminate a process usingTerminateProcess(). |
PROCESS_VM_OPERATION | Required to perform an operation on the address space of a process (see VirtualProtectEx() and WriteProcessMemory()). |
PROCESS_VM_READ | Required to read memory in a process using ReadProcessMemory(). |
PROCESS_VM_WRITE | Required to write to memory in a process using WriteProcessMemory(). |
SYNCHRONIZE | Required to wait for the process to terminate using the wait functions. |
Table 11 | |
Process Working Set
The working set of a program is a collection of those pages in its virtual address space that have been recently referenced. It includes both shared and private data. The shared data includes pages that contain all instructions your application executes, including those in your DLLs and the system DLLs. As the working set size increases, memory demand increases.A process has an associated minimum working set size and maximum working set size. Each time you call CreateProcess(), it reserves the minimum working set size for the process. The virtual memory manager attempts to keep enough memory for the minimum working set resident when the process is active, but keeps no more than the maximum size.To get the requested minimum and maximum sizes of the working set for your application, call the GetProcessWorkingSetSize() function.The system sets the default working set sizes. You can also modify the working set sizes using the SetProcessWorkingSetSize() function. Setting these values is not a guarantee that the memory will be reserved or resident. Be careful about requesting too large a minimum or maximum working set size, because doing so can degrade system performance.
Thread Pooling
There are many applications that create threads that spend a great deal of time in the sleeping state waiting for an event to occur. Other threads may enter a sleeping state only to be awakened periodically to poll for a change or update status information. Thread pooling enables you to use threads more efficiently by providing your application with a pool of worker threads that are managed by the system. At least one thread monitors the status of all wait operations queued to the thread pool. When a wait operation has completed, a worker thread from the thread pool executes the corresponding callback function.You can also queue work items that are not related to a wait operation to the thread pool. To request that a work item be handled by a thread in the thread pool, call the QueueUserWorkItem() function. This function takes a parameter to the function that will be called by the thread selected from the thread pool. There is no way to cancel a work item after it has been queued. Timer-queue timers and registered wait operations also use the thread pool. Their callback functions are queued to the thread pool. You can also use the BindIoCompletionCallback() function to post asynchronous I/O operations. On completion of the I/O, the callback is executed by a thread pool thread.
The thread pool is created the first time you call QueueUserWorkItem() or BindIoCompletionCallback(), or when a timer-queue timer or registered wait operation queues a callback function. By default, the number of threads that can be created in the thread pool is about 500. Each thread uses the default stack size and runs at the default priority. There are two types of worker threads in the thread pool: I/O and non-I/O. An I/O worker thread is a thread that waits in an alertable wait state. Work items are queued to I/O worker threads as asynchronous procedure calls (APC). You should queue a work item to an I/O worker thread if it should be executed in a thread that waits in an alertable state.A non-I/O worker thread waits on I/O completion ports. Using non-I/O worker threads is more efficient than using I/O worker threads. Therefore, you should use non-I/O worker threads whenever possible. Both I/O and non-I/O worker threads do not exit if there are pending asynchronous I/O requests. Both types of threads can be used by work items that initiate asynchronous I/O completion requests. However, avoid posting asynchronous I/O completion requests in non-I/O worker threads if they could take a long time to complete.To use thread pooling, the work items and all the functions they call must be thread-pool safe. A safe function does not assume that thread executing it is a dedicated or persistent thread. In general, you should avoid using thread local storage and queuing asynchronous calls that require a persistent thread, such as the RegNotifyChangeKeyValue() function. However, such functions can be queued to a persistent worker thread usingQueueUserWorkItem() with the WT_EXECUTEINPERSISTENTTHREAD option.Note that thread pooling is not compatible with the single-threaded apartment (STA) model.
Job Objects
A job object allows groups of processes to be managed as a unit. Job objects are namable, securable, sharable objects that control attributes of the processes associated with them. Operations performed on the job object affect all processes associated with the job object. To create a job object, use the CreateJobObject() function. When the job is created, there are no associated processes. To associate a process with a job, use the AssignProcessToJobObject() function. After you associate a process with a job, the association cannot be broken. By default, processes created by a process associated with a job (child processes) are associated with the job. If the job has the extended limitJOB_OBJECT_LIMIT_BREAKAWAY_OK and the process was created with the CREATE_BREAKAWAY_FROM_JOB flag, its child processes are not associated with the job. If the job has the extended limit JOB_OBJECT_LIMIT_SILENT_BREAKAWAY_OK, no child processes are associated with the job.To determine if a process is running in a job, use the IsProcessInJob() function.A job can enforce limits on each associated process, such as the working set size, process priority, end-of-job time limit, and so on. To set limits for a job object, use the SetInformationJobObject() function. If a process associated with a job attempts to increase its working set size or process priority, the function calls are silently ignored.The job object also records basic accounting information for all its associated processes, including those that have terminated. To retrieve this accounting information, use the QueryInformationJobObject() function.To terminate all processes currently associated with a job object, use theTerminateJobObject() function.To close a job object handle, use the CloseHandle() function. The job object is destroyed when its last handle has been closed. If there are running processes still associated with the job when it is destroyed, they will continue to run even after the job is destroyed.If a tool is to manage a process tree that uses job objects, both the tool and the members of the process tree must cooperate. Use one of the following options:
The tool could use the JOB_OBJECT_LIMIT_SILENT_BREAKAWAY_OK limit. If the tool uses this limit, it cannot monitor an entire process tree. The tool can monitor only the processes it adds to the job. If these processes create child processes, they are not associated with the job. In this option, child processes can be associated with other job objects.
The tool could use the JOB_OBJECT_LIMIT_BREAKAWAY_OK limit. If the tool uses this limit, it can monitor the entire process tree, except for those processes that any member of the tree explicitly breaks away from the tree. A member of the tree can create a child process in a new job object by calling the CreateProcess() function with the CREATE_BREAKAWAY_FROM_JOB flag, then calling the AssignProcessToJobObject() function. Otherwise, the member must handle cases in whichAssignProcessToJobObject() fails.
The CREATE_BREAKAWAY_FROM_JOB flag has no effect if the tree is not being monitored by the tool. Therefore, this is the preferred option, but it requires advance knowledge of the processes being monitored.
The tool could prevent breakaways of any kind. In this option, the tool can monitor the entire process tree. However, if a process associated with the job tries to call AssignProcessToJobObject(), the call will fail. If the process was not designed to be associated with a job, this failure may be unexpected.
The Fibers
A fiber is a unit of execution that must be manually scheduled by the application. Fibers run in the context of the threads that schedule them. Each thread can schedule multiple fibers. In general, fibers do not provide advantages over a well-designed multithreaded application. However, using fibers can make it easier to port applications that were designed to schedule their own threads.From a system standpoint, a fiber assumes the identity of the thread that runs it. For example, if a fiber accesses thread local storage (TLS), it is accessing the thread local storage of the thread that is running it. In addition, if a fiber calls the ExitThread() function, the thread that is running it exits. However, a fiber does not have all the same state information associated with it as that associated with a thread. The only state information maintained for a fiber is its stack, a subset of its registers, and the fiber data provided during fiber creation. The saved registers are the set of registers typically preserved across a function call.Fibers are not preemptively scheduled. You schedule a fiber by switching to it from another fiber. The system still schedules threads to run. When a thread running fibers is preempted, its currently running fiber is preempted. The fiber runs when its thread runs.
Before scheduling the first fiber, call the ConvertThreadToFiber() function to create an area in which to save fiber state information. The calling thread is now the currently executing fiber. The stored state information for this fiber includes the fiber data passed as an argument toConvertThreadToFiber().The CreateFiber() function is used to create a new fiber from an existing fiber; the call requires the stack size, the starting address, and the fiber data. The starting address is typically a user-supplied function, called the fiber function, that takes one parameter (the fiber data) and does not return a value. If your fiber function returns, the thread running the fiber exits. To execute any fiber created with CreateFiber(), call the SwitchToFiber() function. You can call SwitchToFiber() with the address of a fiber created by a different thread. To do this, you must have the address returned to the other thread when it calledCreateFiber() and you must use proper synchronization.A fiber can retrieve the fiber data by calling the GetFiberData() macro. A fiber can retrieve the fiber address at any time by calling theGetCurrentFiber() macro.A fiber can use fiber local storage (FLS) to create a unique copy of a variable for each fiber. If no fiber switching occurs, FLS acts exactly the same as thread local storage. The FLS functions (FlsAlloc(), FlsFree(),FlsGetValue(), and FlsSetValue()) manipulate the FLS associated with the current thread. If the thread is executing a fiber and the fiber is switched, the FLS is also switched.To clean up the data associated with a fiber, call the DeleteFiber() function. This data includes the stack, a subset of the registers, and the fiber data. If the currently running fiber calls DeleteFiber(), its thread calls ExitThread() and terminates. However, if a currently running fiber is deleted by another fiber, the thread running the deleted fiber is likely to terminate abnormally because the fiber stack has been freed.
Interprocess Communications Mechanism
Processes frequently need to communicate with other processes. For example when a user process wants to read from a file, it must tell the file process what it wants. Then the file process has to tell the disk process to read the required block. So, there is a need for communication between processes, preferably in a well-structured way not using interrupts. From the applications design, many issue such as race condition (a process that modify/update the shared data providing a wrong data for other processes that share the same data) and deadlock (processes are in the blocked situation forever for the shared resource because no process can take control of the shared resource or hung up waiting for each other to complete their task using the shared resource) exist when shared storage/data involved in this communication among processes.The Microsoft® Windows® operating system provides mechanisms for facilitatingcommunications and data sharing between applications. Collectively, the activities enabled by these mechanisms are called interprocess communications (IPC). Some forms of IPC facilitate the division of labor among several specialized processes. Other forms of IPC facilitate the division of labor among computers on a network.
Typically, applications can use IPC categorized as clients or servers. Aclient is an application or a process that requests a service from some other application or process. A server is an application or a process that responds to a client request. Many applications act as both a client and a server, depending on the situation. For example, a word processing application might act as a client in requesting a summary table of manufacturing costs from a spreadsheet application acting as a server. The spreadsheet application, in turn, might act as a client in requesting the latest inventory levels from an automated inventory control application.After you decide that your application would benefit from IPC, you must decide which of the available IPC methods to use. It is likely that an application will use several IPC mechanisms. The answers to these questions determine whether an application can benefit by using one or more IPC mechanisms.Should the application be able to communicate with other applications running on other computers on a network, or is it sufficient for the application to communicate only with applications on the local computer?
-
Should the application be able to communicate with applications running on other computers that may be running under different operating systems (that is, MS-DOS®, 16-bit Windows®, UNIX)?
-
Should the user of the application have to choose the other application(s) with which the application communicates, or can the application implicitly find its cooperating partners?
-
Should the application communicate with many different applications in a general way, such as allowing cut and paste operations with any other application, or should its communications requirements be limited to a restricted set of interactions with specific other applications?
-
Is performance a critical aspect of the application? All IPC mechanisms include some amount of overhead.
-
Should the application be a GUI application or a console application? Some IPC mechanisms require a GUI application.
The following IPC mechanisms are supported by Windows and discussed in the following sections:
-
Clipboard.
-
COM (Component Object Model).
-
Data Copy.
-
DDE (Dynamic Data Exchange).
-
File Mapping.
-
Mailslots.
-
Pipes.
-
RPC (Remote Procedure Call).
-
Windows Sockets.
Using the Clipboard for IPC
The clipboard acts as a central depository for data sharing among applications. When a user performs a cut or copy operation in an application, the application puts the selected data on the clipboard in one or more standard or application-defined formats. Any other application can then retrieve the data from the clipboard, choosing from the available formats that it understands. The clipboard is a very loosely coupled exchange medium, where applications need only agree on the data format. The applications can reside on the same computer or on different computers on a network. Key Point: All applications should support the clipboard for those data formats that they understand. For example, a text editor or word processor should at least be able to produce and accept clipboard data in pure text format.
Using COM for IPC
Applications that use OLE (Object Linking and Embedding) manage compound documents - that is, documents made up of data from a variety of different applications, link and embed. OLE provides services that make it easy for applications to call on other applications for data editing. For example, a word processor that uses OLE could embed a graph from a spreadsheet. The user could start the spreadsheet automatically from within the word processor by choosing the embedded chart for editing. OLE takes care of starting the spreadsheet and presenting the graph for editing. When the user quit the spreadsheet, the graph would be updated in the original word processor document. The spreadsheet appears to be an extension of the word processor.The foundation of OLE is the Component Object Model (COM). A software component that uses COM can communicate with a wide variety of other components, even those that have not yet been written. The components interact as objects and clients. Distributed COM extends the COM programming model so that it works across a network. Key Point: OLE supports compound documents and enables an application to include embedded or linked data that, when chosen, automatically starts another application for data editing. This enables the application to be extended by any other application that uses OLE. COM objects provide access to an object's data through one or more sets of related functions, known as interfaces.
Using Data Copy for IPC
Data copy enables an application to send information to another application using the WM_COPYDATA message. This method requires cooperation between the sending application and the receiving application. The receiving application must know the format of the information and be able to identify the sender. The sending application cannot modify the memory referenced by any pointers.Key Point: Data copy can be used to quickly send information to another application using Windows messaging.
Using DDE for IPC
DDE (Dynamic Data Exchange) is a protocol that enables applications to exchange data in a variety of formats. Applications can use DDE for one-time data exchanges or for ongoing exchanges in which the applications update one another as new data becomes available.The data formats used by DDE are the same as those used by the clipboard. DDE can be thought of as an extension of the clipboard mechanism. The clipboard is almost always used for a one-time response to a user command, such as choosing the Paste command from a menu. DDE is also usually initiated by a user command, but it often continues to function without further user interaction. You can also define custom DDE data formats for special-purpose IPC between applications with more tightly coupled communications requirements.DDE exchanges can occur between applications running on the same computer or on different computers on a network. Key Point: DDE is not as efficient as newer technologies. However, you can still use DDE if other IPC mechanisms are not suitable or if you must interface with an existing application that only supports DDE.
Using a File Mapping for IPC
File mapping enables a process to treat the contents of a file as if they were a block of memory in the process's address space. The process can use simple pointer operations to examine and modify the contents of the file. When two or more processes access the same file mapping, each process receives a pointer to memory in its own address space that it can use to read or modify the contents of the file. The processes must use a synchronization object, such as a semaphore, to prevent data corruption in a multitasking environment.
You can use a special case of file mapping to provide named shared memory between processes. If you specify the system swapping file when creating a file-mapping object, the file-mapping object is treated as a shared memory block. Other processes can access the same block of memory by opening the same file-mapping object.File mapping is quite efficient and also provides operating-system–supported security attributes that can help prevent unauthorized data corruption. File mapping can be used only between processes on a local computer; it cannot be used over a network. Key Point: File mapping is an efficient way for two or more processes on the same computer to share data, but you must provide synchronization between the processes.
Using a Mailslot for IPC
Mailslots provide one-way communication. Any process that creates a mailslot is a mailslot server. Other processes, called mailslot clients, send messages to the mailslot server by writing a message to its mailslot. Incoming messages are always appended to the mailslot. The mailslot saves the messages until the mailslot server has read them. A process can be both a mailslot server and a mailslot client, so two-way communication is possible using multiple mailslots.A mailslot client can send a message to a mailslot on its local computer, to a mailslot on another computer, or to all mailslots with the same name on all computers in a specified network domain. Messages broadcast to all mailslots on a domain can be no longer than 400 bytes, whereas messages sent to a single mailslot are limited only by the maximum message size specified by the mailslot server when it created the mailslot. Key Point: Mailslots offer an easy way for applications to send and receive short messages. They also provide the ability to broadcast messages across all computers in a network domain.
Using Pipes for IPC
There are two types of pipes for two-way communication: anonymous pipes and named pipes. Anonymous (or unnamed) pipes enable related processes to transfer information to each other. Typically, an anonymous pipe is used for redirecting the standard input or output of a child process so that it can exchange data with its parent process. To exchange data in both directions (duplex operation), you must create two anonymous pipes. The parent process writes data to one pipe using its write handle, while the child process reads the data from that pipe using its read handle. Similarly, the child process writes data to the other pipe and the parent process reads from it. Anonymous pipes cannot be used over a network, nor can they be used between unrelated processes. Named pipes are used to transfer data between processes that are not related processes and between processes on different computers. Typically, a named-pipe server process creates a named pipe with a well-known name or a name that is to be communicated to its clients. A named-pipe client process that knows the name of the pipe can open its other end, subject to access restrictions specified by named-pipe server process. |
After both the server and client have connected to the pipe, they can exchange data by performing read and write operations on the pipe.Key Point: Anonymous pipes provide an efficient way to redirect standard input or output to child processes on the same computer. Named pipes provide a simple programming interface for transferring data between two processes, whether they reside on the same computer or over a network.
Using RPC for IPC
RPC enables applications to call functions remotely. Therefore, RPC makes IPC as easy as calling a function. RPC operates between processes on a single computer or on different computers on a network. A very simple illustration of RPC in UNIX client-server communication is shown in the following Figure.
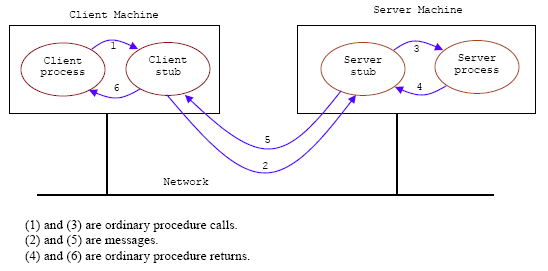
Figure 12
When a client process wants to read a block from a remote file, it calls a procedure (called stub procedure for this case) read on its own machine using normal procedure/function call instruction. read then sends a request message to the file server and waits for the reply. On the server’s machine, the message is accepted by the server stub procedure, which then calls the server using the standard procedure/function call instruction. When the server procedure has done the work, it returns to its caller, the stub, in the usual manner. The server stub then sends a reply message back to the client stub. When the reply arrives, the client stub returns the results to the client procedure in the usual manner. Neither the client procedure nor the server procedure has to know that messages are being used. They just see ordinary procedure calls to local procedures. Only the stubs (in this case) have to know about messages. The stubs are usually library procedures or compiler generated.In this case RPC is used for access to remote service but as if they were on the same machine. The problem may exist for the procedure’s/function’s parameter passing mainly passing by reference (using pointers). The different platforms issue such as Big/Little Endian and data representation also must be taken care.
The traditional RPC is synchronous, which requires that the calling process wait until the called process returns a value. Thus, the synchronous RPC behaves much like a subroutine call. Asynchronous RPC do not block the caller. The replies can be received as and when they are needed, thus allowing client execution to proceed locally in parallel with the server invocation.The RPC provided by Windows is compliant with the Open Software Foundation (OSF) Distributed Computing Environment (DCE). This means that applications that use RPC are able to communicate with applications running with other operating systems that support DCE. RPC automatically supports data conversion to account for different hardware architectures and for byte-ordering between dissimilar environments. RPC clients and servers are tightly coupled but still maintain high performance. The system makes extensive use of RPC to facilitate a client-server relationship between different parts of the operating system. Key Point: RPC is a function-level interface, with support for automatic data conversion and for communications with other operating systems. Using RPC, you can create high-performance, tightly coupled distributed applications.
RPC Components
RPC includes the following major components:
-
MIDL compiler.
-
Run-time libraries and header files.
-
Name service provider (sometimes referred to as the Locator).
-
Endpoint mapper (sometimes referred to as the port mapper).
In the RPC model, you can formally specify an interface to the remote procedures using a language designed for this purpose. This language is called the Interface Definition Language, or IDL. The Microsoft implementation of this language is called the Microsoft Interface Definition Language, or MIDL.After you create an interface, you must pass it through the MIDL compiler. This compiler generates the stubs that translate local procedure calls into remote procedure calls. Stubs are placeholder functions that make the calls to the run-time library functions, which manage the remote procedure call. The advantage of this approach is that the network becomes almost completely transparent to your distributed application. Your client program calls what appear to be local procedures; the work of turning them into remote calls is done for you automatically. All the code that translates data, accesses the network, and retrieves results is generated for you by the MIDL compiler and is invisible to your application.
How RPC Works
The RPC tools make it appear to users as though a client directly calls a procedure (function) located in a remote server program. The client and server each have their own address spaces; that is, each has its own memory resource allocated to data used by the procedure. The following figure illustrates the RPC architecture.
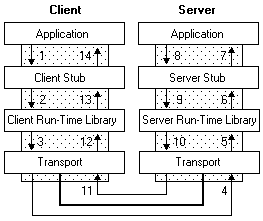
Figure 13
As the illustration shows, the client application calls a local stub procedure instead of the actual code implementing the procedure. Stubs are compiled and linked with the client application. Instead of containing the actual code that implements the remote procedure, the client stub code:
-
Retrieves the required parameters from the client address space.
-
Translates the parameters as needed into a standard NDR format for transmission over the network.
-
Calls functions in the RPC client run-time library to send the request and its parameters to the server.
The server performs the following steps to call the remote procedure.
The server RPC run-time library functions accept the request and call the server stub procedure.
The server stub retrieves the parameters from the network buffer and converts them from the network transmission format to the format the server needs.
The server stub calls the actual procedure on the server.
The remote procedure then runs, possibly generating output parameters and a return value. When the remote procedure is complete, a similar sequence of steps returns the data to the client.
The remote procedure returns its data to the server stub.
The server stub converts output parameters to the format required for transmission over the network and returns them to the RPC run-time library functions.
The server RPC run-time library functions transmit the data on the network to the client computer.
The client completes the process by accepting the data over the network and returning it to the calling function.
The client RPC run-time library receives the remote-procedure return values and returns them to the client stub.
The client stub converts the data from its NDR to the format used by the client computer. The stub writes data into the client memory and returns the result to the calling program on the client.
The calling procedure continues as if the procedure had been called on the same computer.
For Microsoft® Windows®, the run-time libraries are provided in two parts: an import library, which is linked with the application and the RPC run-time library, which is implemented as a dynamic-link library (DLL). The server application contains calls to the server run-time library functions which register the server's interface and allow the server to accept remote procedure calls. The server application also contains the application-specific remote procedures that are called by the client applications.
Microsoft RPC
Microsoft RPC is a model for programming in a distributed computing environment. The goal of RPC is to provide transparent communication so that the client appears to be directly communicating with the server. Microsoft's implementation of RPC is compatible with the Open Software Foundation (OSF) Distributed Computing Environment (DCE) RPC.You can configure RPC to use one or more transports, one or more name services, and one or more security servers. The interfaces to those providers are handled by RPC. Because Microsoft RPC is designed to work with multiple providers, you can choose the providers that work best for your network. The transport is responsible for transmitting the data across the network. The name service takes an object name, such as a moniker, and finds its location on the network. The security server offers applications the option of denying access to specific users and/or groups.In addition to the RPC run-time libraries, Microsoft RPC includes the Interface Definition Language (IDL) and its compiler. Although the IDL file is a standard part of RPC, Microsoft has enhanced it to extend its functionality to support custom COM interfaces.
-------------------------------------------------A break: Some info-------------------------------------------------------
Proxy
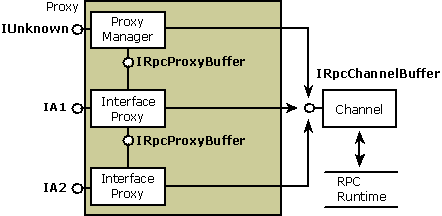
A proxy resides in the address space of the calling process and acts as a surrogate for the remote object. From the perspective of the calling object, the proxy is the object. Typically, the proxy's role is to package the interface parameters for calls to methods in its object interfaces. The proxy packages the parameters into a message buffer and passes the buffer onto the channel, which handles the transport between processes. The proxy is implemented as an aggregate, or composite, object. It contains a system-provided, manager piece called the proxy manager and one or more interface-specific components called interface proxies. The number of interface proxies equals the number of object interfaces that have been exposed to that particular client. To the client complying with the component object model, the proxy appears to be the real object.
Note: With custom marshaling, the proxy can be implemented similarly or it can communicate directly with the object without using a stub.Each interface proxy is a component object that implements the marshaling code for one of the object's interfaces. The proxy represents the object for which it provides marshaling code. Each proxy also implements the IRpcProxyBuffer interface. Although the object interface represented by the proxy is public, the IRpcProxyBuffer implementation is private and is used internally within the proxy. The proxy manager keeps track of the interface proxies and also contains the public implementation of the controlling IUnknown interface for the aggregate. Each interface proxy can exist in a separate DLL that is loaded when the interface it supports is materialized to the client.The following diagram shows the structure of a proxy that supports the standard marshaling of parameters belonging to two interfaces: IA1 and IA2. Each interface proxy implements IRpcProxyBuffer for internal communication between the aggregate pieces. When the proxy is ready to pass its marshaled parameters across the process boundary, it calls methods in the IRpcChannelBuffer interface, which is implemented by the channel. The channel in turn forwards the call to the RPC run-time library so that it can reach its destination in the object.
Figure 14: Structure of the Proxy |
Stub
The stub, like the proxy, is made up of one or more interface pieces and a manager. Each interface stub provides code to unmarshal the parameters and code that calls one of the object's supported interfaces. Each stub also provides an interface for internal communication. The stub manager keeps track of the available interface stubs.There are, however, the following differences between the stub and the proxy:
-
The most important difference is that the stub represents the client in the object's address space.
-
The stub is not implemented as an aggregate object because there is no requirement that the client be viewed as a single unit; each piece in the stub is a separate component.
-
The interface stubs are private rather than public.
-
The interface stubs implementIRpcStubBuffer, not IRpcProxyBuffer.
-
Instead of packaging parameters to be marshaled, the stub unpackages them after they have been marshaled and then packages the reply.
The following diagram shows the structure of the stub. Each interface stub is connected to an interface on the object. The channel dispatches incoming messages to the appropriate interface stub. All the components talk to the channel through IRpcChannelBuffer, the interface that provides access to the RPC run-time library.
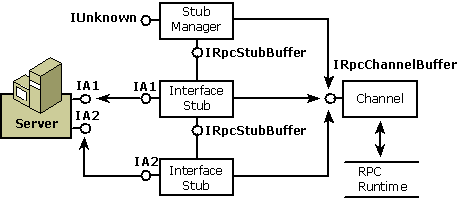
Figure 15: Structure of the Stub
------------------------------------------------------A break----------------------------------------------------------
Using Windows Sockets for IPC
Windows Sockets is a protocol-independent interface. It takes advantage of the communication capabilities of the underlying protocols. In Windows Sockets 2, a socket handle can optionally be used as a file handle with the standard file I/O functions.
Windows Sockets are based on the sockets first popularized by Berkeley Software Distribution (BSD). An application that uses Windows Sockets can communicate with other socket implementation on other types of systems. However, not all transport service providers support all available options.
Key Point: Windows Sockets is a protocol-independent interface capable of supporting current and emerging networking capabilities.
---------------------------------------------End Windows 2000, Xp Pro Processes & Threads----------------------------------------------
Further reading and digging:
Microsoft C references, online MSDN.
Microsoft Visual C++, online MSDN.
ReactOS - Windows binary compatible OS - C/C++ source code repository, Doxygen.
Linux Access Control Lists (ACL) info can be found atAccess Control Lists.
For Multi bytes, Unicode characters and Localization please refer to Locale, wide characters & Unicode (Story) and Windows users & groups programming tutorials (Implementation).
Structure, enum, union and typedef story can be found C/C++ struct, enum, union & typedef.
Check the best selling C / C++ and Windows books at Amazon.com.