|< Intro To Buffer Overflow Study |BOF Main Page |Preparing The Vulnerable Environment > |
CHAPTER TWO:
THREATS, TECHNIQUES & PROCESSOR EXECUTION ENVIRONMENT
What are in this section?
2.1 The Current Trends
2.2 Detection and Prevention Solutions
2.3 The Current Implementation
2.4 The Exploit Advancement
2.5 Intel Processor Execution Environment
2.5.1 Memory
2.5.2 Registers
2.5.3 Procedure Call
2.5.3.1 Stack
2.5.3.2 General Task of the Stack Set up
2.5.3.3 Procedure Linking Information
2.5.3.4 Calling Procedures Using CALL and RET
2.6 Related Instructions and Stack Manipulation
2.1 The Current Trends
In this chapter, we will have some reviews on what have been done in the previous decades for buffer overflow. We will also try to understand the techniques used in the detection and protection schemes or mechanisms and their respective weaknesses and strengths. From various computer security reports and advisories, buffer overflow still one of the top vulnerabilities and exploits. A senior editor of Dark Reading, Kelly Jackson Higgins [4] wrote that research data from Telus, an Internet Service Provider (ISP) company, which provides vulnerability research analysis to the most of the top 20 security vendors in the world, mentioned that buffer overflow is still retaining a top threat based on the report for enterprise class products category. According to Cisco Annual Security Report [5], under the vulnerability and threat categories as shown in Figure 2.1, buffer overflow is the number one threat and vulnerability from January through October 2007 followed by the Denial-of-Service (DOS). The interesting part of this report is the third and fourth threats: Arbitrary Code Execution and Privilege Escalation which is a publicly known that buffer overflow vulnerability can lead to these two threats.
Figure 2.1: Top 20 threats and vulnerabilities, January - October 2007 [5] |

In Cisco case, buffer overflow problems normally related to its Internetwork Operating System (IOS). IOS is a multitask, embedded OS used in its router and switch products. Cisco is one of the biggest manufacturer and vendor for networking products that build our network infrastructure. In countering and providing solutions for those threats, Cisco has it own security advisories.
Under the threats and vulnerabilities trend shift, from the same report as shown in Table 2.1, buffer overflow shows an increase of 23% compared to the same time period in 2006 and except the software fault, others show decrementing trends.
Table 2.1:Shifts in threats and vulnerabilities reported [5]
Threat category | Alert count | % change from 2006 |
Arbitrary Code Execution | 232 | -24% |
Backdoor Trojan | 15 | -72% |
Buffer Overflow | 395 | 23% |
Directory Traversal | 17 | -52% |
Misconfiguration | 8 | -57% |
Software Fault (Vul) | 98 | 53% |
Symbolic Link | 5 | -64% |
Worm | 37 | -28 |
In this case, other than having high competency in C programming, to fully understand the vulnerable, researcher needs to be fluent in the IOS commands and its functionalities.
When referring to the Vulnerability Type Distributions in Common Vulnerabilities and Exposures, CVE [6], buffer overflow and its variant dominated the reported advisories. The categories and the trend analysis from 2001 – 2006 have been summarized in the following Table.
Table 2.2: Summary of the vulnerability type distribution for 2001 – 2006
CVE category | 2001 – 2006 analysis |
Result summary | Buffer overflow is still the number 1 problem reported in OS vendor advisories. |
Overall trends | Dominated by buffer overflow year after year before 2005 as reported in the OS vendor advisories. Although the percentage of buffer overflows has declined, the buffer overflow variants such as integer overflows, signedness errors, and double-frees have been in increase. |
OS vs. non-OS | An increase in Integer overflows reported in OS vendor advisories. These vulnerabilities and exploits include software that related to the kernel, cryptographic modules, and multimedia file processors such as image viewers and music players and after 2004, many issues occur in libraries or common DLLs were reported. |
Open and Closed Source | With the exception of 2004, buffer overflows are number one for both open and closed source, with roughly the same percentage in each year. |
The overall CVE by category dominated by buffer overflow problem. Obviously, we are not just seeing the classic types of buffer overflow decreasing in trend, new buffer overflow variants such as signedness errors and double-frees also are in the increasing trends. Again, not just an average programming skill, the knowledge and skill in system or kernel programming is needed in order to provide an effective counter measure to the vulnerability as shown in the OS and non-OS exploit.
When searching for C and C++ open source projects at Sourceforge.net and the applications developed using C++ at Bjarne Stroustrup [7] personal site, C and C++ still dominate as programming languages of choice for applications from system to the Internet browser. While solving the current buffer overflow problem, it is likely that we will still need to deal with buffer overflow for another decade.
2.2 Detection and Prevention Solutions
There is already much information demonstrating how the buffer overflow happen [8], [9], [10], [11] on various platforms and applications. Similarly, there are also many solutions proposed and implemented. The solutions vary from a very simple check list [12] and signature based [13], [14], kernel patch [15], [16], hardware based [17], [18], [19], [20], [21], [22], [23], compiler extensions and tools [24], [25], [26], [27], [28], [29], [30], static source code analysis [31], using secure library [32] and many more [33]. [34], [35], [36], [37], [38], [39].
Although using the same C or C++ source codes, buffer overflow is specific to the architecture. Hence, solutions normally specific to the architecture that having different instructions set. In this case, the exploit must also match to the architecture used though just with a little code modifications. On the other hand, solutions also suffer the same issue. Some solutions just provide the detection without prevention. Some provide detection and prevention but specific to the certain type of buffer overflow variant only. Other solutions suffer unacceptable overheads that affect the performance.
2.3 The Current Implementation
Current implementation is bias to the kernel side of the OS and compiler extension. As an example, PaX project [15] is a Linux kernel patches that designed to protect from buffer overflow. The PaX’s NOEXEC component provides a protection to prevent the injection and execution of arbitrary code in an existing process’s memory space. Meanwhile, the Address Space Layout Randomization (ASLR) provides the randomness to the layout of the virtual memory space. By randomizing the locations of the heap, stack, loaded libraries and executable binaries during every boot-up, ASLR supposed to effectively reduce the probability of the exploit that relies on fixed or hardcoded addresses within those segments that will successfully redirect code execution to the supplied buffer or other part of the memory area. A similar implementation also available on Windows x64 platform which called PatchGuard.
StackGuard [24] is another protection mechanism implemented in GCC compiler which based on modifications to the stack layout and/or the use of canaries. Other similar mechanisms include StackShield [25] and ProPolice SSP [27].
Microsoft’s proprietary solution is considered similar to the StackGuard which implemented in the new .NET compilers. For example, Microsoft provides the /GS option [26] for the command line or IDE compilation. When enabling this option, a security cookie (canary), is placed in front of the return address and the saved ebp register. If this cookie is corrupted or overwritten, then the return address also will be overwritten, means that the return address has been changed. By default, Windows 2003 is compiled with this stack protection enabled. Unfortunately, for all the previously mentioned implementations, except the PaX (latest version) can be defeated successfully [40], [41], [42].
On the processor side, an AMD CPU [43] uses the NX flag bit, which stands for No eXecute, to flag a portion of memory for the no execute feature. Any section of memory designated with the NX attribute means that it cannot be executed. Intel has the same implementation using the XD bit, that stands for eXecute Disable. Both of these implementations need the OS support and can be enabled or disabled. For example, the XD implementation can be obviously seen in the Windows OS through the Data Execution Prevention (DEP) setting. However, both implementations can be bypassed [44], [45], [46].

Figure 2.2: Windows Data Execution Prevention (DEP) setting
In 2005 (latest updated version is in 2007), the ISO/IEC committee for the standard C published the extension for the C library which is part of addressing the buffer overflow issue. The first part of the extension [47] is for the bound-checking recommendations for the related C libraries mainly used in string and character manipulation such as stdio.h and string.h and the second part [48] defines specification for the dynamic allocation functions. However, the implementer of the C/C++ already incorporated the recommendations earlier, for example, the Microsoft Visual C++ .NET 2005 as can be seen on the introduction of the secure C function version for the string and character such as strcpy_s() and scanf_s(). On the other hand, CERT through its Secure Coding Initiative publishes its own standard [49] to support and encourage the practice of secure coding for C and C++. Alsobooks related to the secure coding have been published long ago.
2.4 The Exploit Advancement
Most of the protection and prevention used can be compromised or bypassed. It is clear that every single solution will have their respective weaknesses. In the meantime, research for the exploits always one step ahead. For example, the polymorphic type of exploit [50], [51], [52], [53] can bypass the signature based scanning technique such as used antivirus software easily, though there are solutions for this [54], [55]. In this case, the shellcode that used as the buffer overflow payload implemented having polymorphic characteristic in order to avoid a pattern or signature based detection tools or algorithms.
Another more potent and stealthy type, uses the rootkit technique. In this case only the kernel level detection and/or protection mechanism is a viable solution that involves device driver or kernel programming. Keep in mind that Windows also is not spared from rootkit which historically comes from UNIX. We can also expect possibility of different threat and vulnerability that have been combined together leading to the more resilient attack and exploit. For example, buffer overflow vulnerable can be used as an exploit while social engineering technique will be the trigger point.
2.5 Intel Processor Execution Environment
Before analyzing the flow of event when doing the experimental demonstration, it is important to understand the related information regarding the execution environment of the Intel processor for operating system and application program. This discussion is based on the Intel Core 2 Duo processor family (as used in the demonstration) and restricted to IA-32 architecture. The complete information can be found in [56].
The execution environment provided by the processor will be used jointly by operating system and application program or other executive that running on the processor. In the demonstration, the OS, programming language and program such as the vulnerable code flow of event is closely related to the processor execution environment.
2.5.1 Memory
Memory as a secondary storage, installed in the computer system is called physical memory. It is arranged as a sequence of 8-bit bytes and each byte is assigned a unique address normally called physical address. The maximum range of the address space depends on the architecture of the system for example if the processor does not support 64 bit, the maximum address space is up to 236 -1 (64 GBytes).
However OS normally uses the processor’s memory management facilities (Memory Management Unit – MMU) to access the physical memory in order to provide efficiency such as utilizing the paging and segmentation features. The processor accesses the physical memory indirectly using one of the following three memory models.
Flat memory model – In this model, memory seen by a program as a single, contiguous address space which called a linear address space. All code, data and stack are contained in this single address space and any addressable location in the memory space is called linear address.
Segmented memory model – Memory seen by a program as a group of independent address spaces called segments. Normally, code, data and stack contained in separate segments. In order to address a byte in a segment, a program will use a logical address. The logical address consists of segment selector and an offset. The segment selector identifies the segment to be accessed while the offset identifies a byte in the address space of the segment. All the segment actually mapped to the processor’s linear address space and it is processor’s responsibility to translate each logical address into the respective linear address. This model is most widely adopted in the implementation.
Real-address mode memory model – This is Intel 8086 processor’s memory model provided to support compatibility with the existing programs which are written to run on the Intel 8086 processor. The linear address space for the program and OS consist of an array of segments of up to 64 KBytes is size each.

Figure 2.3: The three memory management models
Linear address space is mapped into the processor physical address space either directly or through paging for flat or segmented memory model. When the paging is disabled, each linear address will be mapped to one-to-one respective physical memory. In this case, linear addresses are sent out on the processor’s address lines without any translation. If the paging mechanism is enabled, the linear address space is divided into pages which are mapped tovirtual memory. The virtual memory pages then mapped as needed into physical memory.
2.5.2 Registers
The IA-32 architecture provides 16 registers for the general system and application programming utilization. These registers can be grouped into the following categories.
8 general-purpose registers – for storing operands and pointers.
6 segment registers – for holding segment selectors.
1 EFLAGS register – for program status and control purposes.
1 EIP (instruction pointer) register – used to point to the next instruction to be executed.

Figure 2.4: The general system and application programming registers

Figure 2.5: The alternate general-purpose register names

Figure 2.6: System Flags in the EFLAGS Register
These 32-bit general-purpose registers (EAX,EBX,ECX,EDX,ESI,EDI,EBP and ESP) are used for holding operands for logical and arithmetic operations and for address calculation and memory pointers. However Intel’s instruction set combined with the segmented memory model normally use these general purpose registers for specific usage that can be summarized in the following Table.
Table 2.3: The 32-bit general-purpose registers
Register | Usage |
EAX | Accumulator for operands and results data. |
EBX | Pointer to data in the DS segment. |
ECX | Counter for string and loop operation. |
EDX | I/O pointer |
ESI | Pointer to data in the segment pointed to by the DS register, source pointer for string operations |
EDI | Pointer to data (or destination) in the segment pointed to by the ES register, destination pointer for string operations. |
ESP | Stack pointer (in SS segment). |
EBP | Pointer to data on the stack (in the SS segment) |
The segment registers (CS,DS,SS,ES,FS and GS) used to hold the 16-bit segment selectors. A segment selector is a special pointer that identifies a segment in memory. If writing the system code, coders may need to create segment selectors directly while if writing application code, coders normally create segment selector with assembler directives and symbols. Then, it is the assembler and other tools responsibility to create the actual segment selector values associated with these directives and symbols.
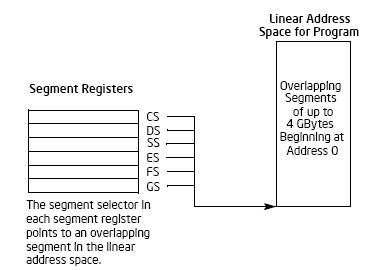
Figure 2.7:The use of segment registers for flat memory model
Figure 2.8: The use of segment registers in segmented memory model |


Figure 2.9: The default segment selection rules
The special register,EIP contains the offset in the current code segment for the next instruction to be executed. Depending on the system architecture either 16- or 32-bit,EIP is advanced from one boundary to the next or it is moved forward or backward by a number of instructions when executing unconditional branch instruction such as JMP and CALL or conditional branch such as JCC.
Take note that EIP cannot be accessed directly by software, it is controlled implicitly by the control-transfer instructions such as JMP,CALL,RET and JCC, interrupts and exceptions. The only way to read the EIP register is to execute the CALL instruction and then read the value of the return instruction pointer from the procedure stack. The EIP register can be loaded indirectly by modifying the value of a return instruction pointer on the procedure stack and executing a return instruction such asRET and IRET. This behaviour is important when finding or determining the address of a string in the stack used in the buffer overflow exploit that will be discussed in Chapter 3.
2.5.3 Procedure Call
In this section, the 'procedure' term used as a general ‘phrase’ for discussing other similar names used in the programming language such as function, subroutine and method. It is important in order to understand how the stack will be constructed and destroyed from the processor’s 'point-of-view'. Intel processor support the following two ways of procedure calls.
Using the CALL and RET instructions.
Using the ENTER and LEAVE instructions, associated with the CALL and RET instructions.
These two procedure call mechanisms use in the stack construction and destruction which include saving the state of calling procedure, passing parameters to the called procedure (callee) and storing local variables for the currently executing procedure.
2.5.3.1 Stack
The stack structure is shown in Figure 2.10. It is just an array of 'bounded' contiguous memory locations and contained in a segment which identified by the segment selector in the SS register. It is quite similar to what C compiler implements for its function call which we will discuss later.

Figure 2.10: A structure of stack
The stack can be located anywhere in the linear address space for program in flat memory model and can be up to 4GBytes long, which is a maximum size of a segment.
Normally, the PUSH instruction used to store items on the stack while POP instruction used to remove items from the stack. The ESP will be decremented when an item is pushed onto the stack, writing the item at the new top of the stack. When an item is popped off the stack, the processor reads the item from the top of the stack and then increments the ESP register. Well, it is obvious that the PUSH and POP operate on the First-In-Last-Out manner.
Notice that when items are pushed on the stack, the stack grows downward in memory and when the items are popped from the stack it shrinks upward. A program or OS can set up many stacks and the number of stacks in a system is limited by the maximum number of segments and the availability of the physical memory. However, at anytime, only one stack that is the current stack is available which the one that is contained in the segment referenced by the SS register. For all the stack operation, processor will reference the SS register automatically. In this case the CALL,RET,POP,PUSH,LEAVE and ENTER instructions all will perform operations on the current stack.
2.5.3.2 General Task of the Stack Set up
Now, let see how the stack is setup in conjunction with the procedure call. In general, to set up a stack and establish it as the current stack, programs or OS must do the following tasks.
Establish a stack segment (SS).
Load the segment selector for the stack segment into theSS register using MOV,POP or LSS instruction.
Load the stack pointer for the stack into the ESP using MOV,POP or LSS instruction.
Depending on the width of the stack, the stack pointer for the stack segment should be aligned to 16-bit (word) or 32-bit (double-word) size. The POP and PUSH instructions use the D flag in the segment descriptor to determine how much to decrement or increment the stack pointer on a push or pop operation respectively. However, if the contents of a segment register (a 16-bit segment selector) are pushed onto the 32-bit wide stack, processor automatically aligns the stack pointer to the next 32-bit boundary. It is the programs, tasks and system procedures that running on the processor responsibility to maintain a proper alignment of the stack pointers, the processor does not verify stack pointer alignment.
2.5.3.3 Procedure Linking Information
The procedure linking information will be used in conjunction with the standard program procedure call technique that implemented by procedures such as function, subroutine and method in programming languages. Processor provides two pointers to link the procedures:
A stack-frame base pointer.
A return instruction pointer.
In real implementation the stack is normally divided into frames. Each stack is a self-contained storage that may include local variables, parameters to be passed to another procedure and procedure linking information. The stack-frame base pointer contained in the EBP register identifies a fixed reference point within the stack frame for the called procedure. In this case, the called procedure normally will copy the content of the ESP register into EBP register before pushing any local variables on the stack. Then, the stack-frame base pointer provides an access to the stack data structure such as return instruction pointer and local variables.
For the return instruction pointer, the CALL instruction pushes the address in the EIP register onto the current stack before jumping to the first instruction of the called procedure. Then, this address becomes the return-instruction pointer and pointing to the instruction where the execution of the calling procedure should continue. Programmer need to ensure that the stack pointer is pointing to the return instruction pointer on the stack before issuing a RET instruction because processor does not keep track of the location of the return-instruction pointer. A typical practice to reset the stack pointer back to point to the return-instruction pointer is to move the contents of the EBP register into the ESP register as shown in the following assembly snippet.
...
subprog_label:
...
PUSH EBP ; save original EBP value on stack
MOV EBP, ESP ; new EBP = ESP
SUB ESP, LOCAL_BYTES_SIZE ; the # of bytes needed by locals
...
; subprogram code
...
MOV ESP, EBP ; deallocate locals
POP EBP ; restore original EBP value
RET
In this case, one of the weakness that can be misused is the processor does not require that the return instruction pointer point back to the calling procedure. Before executing the RET instruction, the return instruction pointer can be manipulated in program to point to any address in the current code segment (near return) or another code segment (far return).
2.5.3.4 Calling Procedures Using CALL and RET
In order to provide control transfers to procedure within the current code segment (near call) and in different code segment (far call) the CALL instruction can be used. Near calls generally provide access to the local procedures within the currently running program while the far calls are typically used to access OS procedures or procedures in a different task.
The RET instruction provides near and far returns to match the near and far versions of CALL instruction. The RET instruction also allows a program to increment the stack pointer on a return to release parameters from the stack. The following steps describe the near call execution.
Pushes the current value of the EIP register on the stack.
Loads the offset of the called procedure in the EIP register.
Begins execution of the called procedure.
When executing the near return, the following steps are performed.
Pops the top of the stack value that is the return instruction pointer into the EIP register.
If the RET instruction has an optional x number of argument, increments the stack pointer by the number of the bytes specified with the x operand to release parameters from the stack.
Continues execution of the calling procedure.
When executing a far call, the following steps are performed.
Pushes the current value of the CS register on the stack.
Pushes the current value of the EIP register on the stack.
Loads the segment selector of the segment that contains the called procedure in the CS register.
Loads the offset of the called procedure in the EIP register.
Begins execution of the called procedure.
Finally, when executing a far return, the following steps performed by processor.
Pops the top of the stack value that is the return instruction pointer into the EIP register.
Pops the top of the stack value that is the segment selector for the code segment being returned to into the CS register.
If the RET instructions has an optional x number of argument, increments the stack pointer by the number of bytes specified with the x operand to release parameter from the stack.
Continues execution of the calling procedure.
In order to pass parameters between procedures, one of the following three methods can be used.
Using the general-purpose registers – On the procedure calls, processor does not save the state of the general-purpose registers so a calling procedure can pass up to six parameters to the called procedure by copying the parameters into any of these registers except of course the ESP and EBP before executing the CALL. Similarly, the called procedure can pass parameters back to the calling procedure through these registers.
Using the stack – This is suitable for the large number of parameters that need to be passed to the called procedure. The parameters can be stored in the stack of the stack frame. The EBP can be used to make a frame boundary for easy access to the parameters. Similarly, the called procedure can pass parameters back to the calling procedure using stack.
Using an argument list – Argument list in one of the data segments in memory can be used to pass a large number of parameters or even a data structure to the called procedure. Then general-purpose register or stack can be used to store a pointer to the argument list. Similarly, parameters can also be passed back to the caller in the same manner.
During the procedure call, processor does not save the contents of the segment, general-purpose or the EFLAGS registers. It the caller responsibility to explicitly save the values that will be needed later for execution continuation after a return in any of the general-purpose registers. In this case PUSHA (push all) and POPA (pop all) instructions can be used for saving and restoring the contents of the general-purpose registers. Take note that PUSHA pushes the values in all the general-purpose registers on the stack in the following order: EAX,ECX,EDX,EBX,ESP (the value before executing the PUSHA instruction), EBP,ESI and EDI. The POPA instruction pops all the register values saved with a PUSHA instruction (except the ESP value) from the stack to their respective registers. Before returning to the calling procedure, called procedure need to restore the state of any of the segment registers explicitly if they are changed. For maintaining the state of the EFLAGS registers, the PUSHF/PUSHFD and POPF/POPFD instructions can be used.
The IA-32 architecture has an alternative method for performing procedure calls with the ENTER (enter procedure) and LEAVE (leave procedure) instructions. Using these instructions, the stack frame will be automatically created and released automatically. Predefined spaces for local variables and the necessary pointers already available in the stack frame and scope rules features also available. This block-structured procedure calls technique is normally used by the high level languages such as C and C++. The detail of this procedure call technique can be found in [56].
2.6 Related Instructions and Stack Manipulation
This section introduces the basic Intel’s instruction set used in the stack operations. It is discussed in order to learn the basic instructions used to manipulate the stack and it is not complete information which can be found in Intel’s doc. The PUSH,POP,PUSHA and POPA instructions can be used to move data to and from the stack. In general, thePUSH instruction decrement the stack pointer (ESP) then copies the source operand to the top of the stack. It operates on memory, immediate and register operands (including the segment registers). The general syntax is:
PUSHSource
It is used to store parameters on the stack before calling a procedure and reserving space on the stack for temporary variables. Figure 2.11 tries to describe the PUSH operation in placing a doubleword, 'ABCD' into the stack.

Figure 2.11: The PUSH operation
The PUSHA instruction saves the contents of the eight general-purpose registers on the stack. This instruction simplifies the procedure calls by reducing the number of instructions needed to save the contents of the general-purpose registers as discussed previously, the registers are pushed on the stack in the order of EAX,ECX,EDX,EBX, the initial value of ESP before EAX was pushed, EBP,ESI and EDI. Figure 2.12 shows the PUSHA operation.

Figure 2.12: The PUSHA operation
Opposite to PUSH, the POP instruction copies the word or doubleword at the current top of the stack (ESP) to the location specified with the destination operand. The general syntax is:
POPDestination
The ESP then incremented to point to the new top of the stack. The destination operand may specify a general-purpose register, a segment register or memory location. Figure 2.13 shows the POP operation in removing a doubleword, 'ABCD' from the stack.

Figure 2.13: The POP operation
The POPA instruction reverses the PUSHA actions. It pops the top eight words or doublewords from the top of the stack into the general-purpose registers, except the ESP register. If the operand-size attribute is 32, the doublewords on the stack are moved to the registers in the order of EDI,ESI,EBP, ignoring the doubleword, EBX,EDX,ECX and EAX. The ESP register is restored by the action of popping the stack. If the operand-size attribute is 16, the words on the stack ate moved in the order of DI,SI,BP, ignoring the word, BX,DX,CX and AX. Figure 2.14 shows the POPA operation.

Figure 2.14: The POPA operation
There are conditional and unconditional control transfer instructions available to direct the flow of program execution in Intel’s instruction set. The unconditional control transfers are always executed while the conditional transfers are executed only for specified states of the status flags in the EFLAGS register. Only several unconditional transfer instruction will be discussed here that related to the buffer overflow exploit preparation and stack construction.
The JMP,CALL,RET,INT and IRET instructions can be used to transfer program control to another location that is the destination address in the instruction stream. The destination can be within the same code segment (near transfer) or in a different code segment (far transfer). The jump (JMP) instruction has the following characteristics.
Unconditional transfer program control to a destination instruction.
One-way transfer, the return address is not saved.
Destination operand specifies the address of the destination instruction.
Then, the address can be relative or absolute.
The CALL (call procedure) instruction and RET (return from procedure) instructions can be used for jumping from one procedure to another and subsequent jump back or return to the calling procedure. TheCALL instruction transfers program control from the current or calling procedure to another procedure that is the called procedure. To allow a subsequent return to the calling procedure, the CALL instruction saves the current contents of the EIP register on the stack before jumping to the called procedure. Before transferring program control, the EIP register contains the address of the instruction following the CALL instruction. This address is referred as the return instruction pointer or return address when it is pushed on the stack. The address of the first instruction in the procedure being jumped to, specified in a CALL instruction the similar way as it is in a JMP instruction and the address can be a relative or absolute address. If an absolute address is specified, it can be either a near or a far pointer.
The RET instruction transfers program control from the procedure currently being executed that is the called procedure, back to the procedure that call it, that is the calling procedure. Transfer of control is achieved by copying the return instruction pointer from the stack into the EIP register. Then, the program execution resumes with the instruction pointed to by the EIP. The optional operand if used is the value of which is added to the contents of the ESP as part of the return operation and this operand permits the stack pointer to be incremented in order to remove parameters from the stack that were pushed on the stack by the calling procedure previously. The following C and assembly code snippet shows the PUSH,POP,JMP and RET instructions.
The C code:
void compute sum(int n, int *sumptr)
{
int i , sum = 0;
for (i=1; i <= n; i++)
sum += i;
*sumptr = sum;
}
The assembly equivalent:
cal_sum:
PUSH EBP
MOV EBP, ESP
SUB ESP, 4 ; make room for local sum
MOV DWORD [EBP - 4], 0 ; sum = 0
MOV EBX, 1 ; EBX (i) = 1
for_loop:
CMP EBX, [EBP+8] ; is i <= n?
JNLE end_for ; if i > n, jump to end_for
ADD [EBP-4], EBX ; sum += i
INC EBX
JMP SHORT for_loop ; jump to for_loop
end_for:
MOV EBX, [EBP+12] ; EBX = sumptr
MOV EAX, [EBP-4] ; EAX = sum
MOV [EBX], EAX ; *sumptr = sum;
MOV ESP, EBP
POP EBP
RET
The following assembly snippet shows the CALL instruction.
…
MOV EBX, input1
CALL wri_int ; first call
MOV EBX, input2
CALL wri_int ; second call
…
wri_int:
CALL read_int ; another call
MOV [EBX], EAX
RET
To conclude this section, let recap what have been covered. The PUSH instruction inserts a double word (or word or quad word) on the stack by subtracting 4 from ESP and then stores the double word at ESP. The POP instruction reads the double word at ESP and then adds 4 to ESP. The following assembly code demonstrates how these instructions work and assumes that ESP is initially holds 1000H.
PUSH DWORD 7 ; 7 stored at 0FFCh, ESP = 0FFCh
PUSH DWORD 3 ; 3 stored at 0FF8h, ESP = 0FF8h
PUSH DWORD 5 ; 5 stored at 0FF4h, ESP = 0FF4h
POP EAX ; EAX = 5, ESP = 0FF8h
POP EBX ; EBX = 3, ESP = 0FFCh
POP ECX ; ECX = 7, ESP = 1000h